DATEDIFF is one of the most
widely used built-in functions to calculate the difference between two date
points. Microsoft says “DATEDIFF can be used in the select list, WHERE,
HAVING, GROUP BY and ORDER BY clauses”. Programmatically
and logically this statement is absolutely correct, however there is a catch
when it is used on the WHERE clause. We often introduce “non-sargable”
predicate with the DATEDIFF function which leads to poor performance. I don’t
think that there are good guidelines for many new developers.
Usage patterns:
As a rule of thumb, we
know that using function on the left side of the WHERE clause causes Table or
Index scan. So when the DATEDIFF function or any other functions are used on a
key column, we will obviously see performance issues. Some common patterns of
DATEDIFF functions are as follows:
WHERE DATEDIFF(day, dJoinDate, @CurrentDate) >=30
WHERE DATEDIFF(d, dDateofBirth, @dDate) =0
WHERE a.LastName LIKE 'Jon*' AND DATEDIFF(d, a.dSalesDate, @dDate) =0
WHERE DATEDIFF(mm, dDate, GetDate()) >= 15
WHERE YEAR(a.dDate) =2012
Issues observed:
Following are some
definite issues which can be observed:
1.
Increased query
response times.
2.
Table/Index scan
in execution plans.
3.
Short or long
durations of SQL blockings.
4.
Increasing of locking
overhead.
5.
Unnecessary I/O
activities and memory pressure.
6.
Parallel query
plan and “sort operation”.
Sample Scripts to
understanding the performance issues:
Let’s create a database
and table; and then populate the table with data to explore some of the
performance issues which may arise from a non-sargable predicates.
/******************************************************
Create database and some relevant stuff
******************************************************/
set nocount on
create database TestDB
go
use TestDB
go
if object_id('tblLarge') is not null
drop table tblLarge
go
create table tblLarge
(
xID int identity(1, 1) ,
sName1 varchar(100) ,
sName2 varchar(1000) ,
sName3 varchar(400) ,
sIdentifier char(100) ,
dDOB datetime null ,
nWage numeric(20, 2) ,
sLicense varchar(25)
)
go
/******************************************************
Add some records with non-blank dDOB
******************************************************/
set nocount on
insert into tblLarge
( sName1
,
sName2 ,
sName3 ,
sIdentifier ,
dDOB ,
nWage ,
sLicense
)
values
( left(cast(newid() as varchar(36)), rand() * 50) , -- sName1
left(cast(newid() as varchar(36)), rand() * 60) , -- sName2
left(cast(newid() as varchar(36)), rand() * 70) , -- sName2
left(cast(newid() as varchar(36)), 2) , -- sIdentifier
dateadd(dd, -rand() * 20000, getdate()) , -- dDOB
( rand() * 1000 ) , -- nWage
substring(cast(newid() as varchar(36)), 6, 7) --
sLicense
)
go 100000
/******************************************************
Create indexes
******************************************************/
alter table dbo.tblLarge add constraint
PK_tblLarge primary
key clustered
(
xID
) with( pad_index = off,
fillfactor = 85,
allow_row_locks
= on,
allow_page_locks
= on)
go
create nonclustered index [IX_tblLarge_dDOB_sName1]
on [dbo].[tblLarge]
( [dDOB] asc,
[sName1] asc
) with (pad_index = off,
allow_row_locks
= on,
allow_page_locks
= on,
fillfactor = 85)
go
Example #1: DATEDIFF:
non-sargable predicate:
Let’s consider the following commonly used patterns of the DATEDIFF
function:
declare @dDate as datetime
set @dDate = '2012-09-19'
-- #0: non-sargable search
select xID ,
sName1 ,
dDOB
from tblLarge
where datediff(d, dDOB, @dDate) = 0
order by dDOB
The above query
results with Index Scan and below is the execution plan:

Optimizing
the search:
The above
query can be optimized a couple different ways and will result in an efficient
execution plan:
-- #1: sargable predicate
select xID ,
sName1 ,
dDOB
from tblLarge
where dDOB between '20120919' and '20120920'
order by dDOB
-- #2: sargable predicate
select xID ,
sName1 ,
dDOB
from tblLarge
where dDOB between cast(convert(varchar(12), @dDate, 112) + ' 00:00:00' as datetime)
and cast(convert(varchar(12), @dDate + 1, 112) + ' 00:00:00' as datetime)
order by dDOB
-- #3: sargable predicate
select xID ,
sName1 ,
dDOB
from tblLarge
where dDOB between convert(char(8), @dDate, 112)
and convert(char(8), @dDate + 1, 112)
order by dDOB
Following are the execution plans and cost
comparisons:

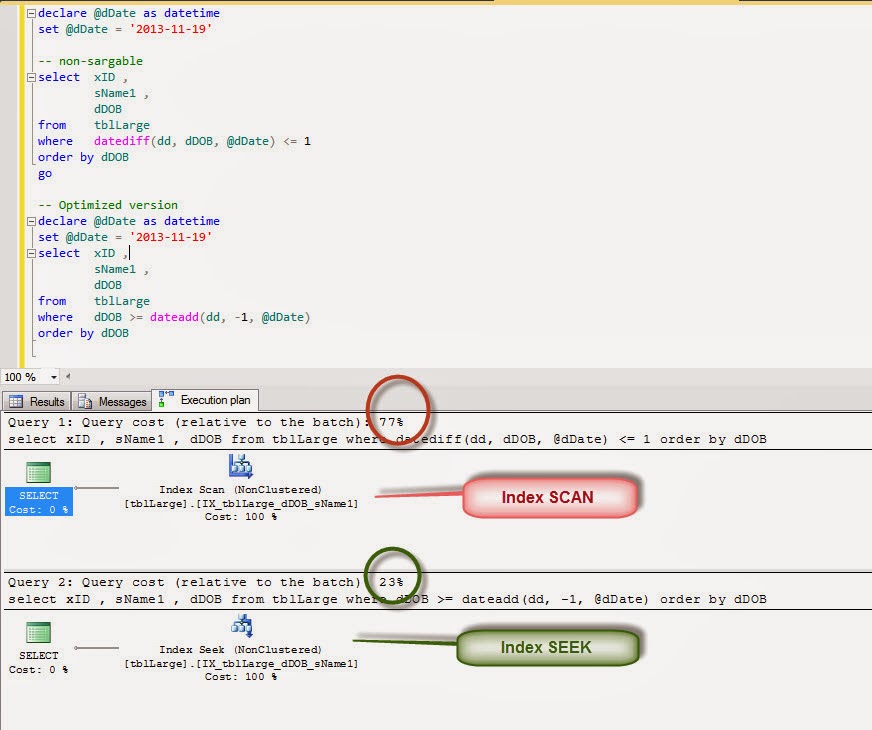
Example #2: DATEDIFF:
non-sargable predicate:
Consider
the following as a non-sargable example.
declare @dDate as datetime
set @dDate = '2013-11-19'
select xID ,
sName1 ,
dDOB
from tblLarge
where datediff(dd, dDOB, @dDate) <= 1
order by dDOB
To
optimize the above query we can move the DATEDIFF function from left side to
the right side.
declare @dDate as datetime
set @dDate = '2013-11-19'
select xID ,
sName1 ,
dDOB
from tblLarge
where dDOB >= dateadd(dd, -1, @dDate)
order by dDOB
Following is the optimization effort which results
in better query response time.
Example #3: YEAR-
non-sargable predicate:
This is an
example of YEAR function used on datetime column which results with index scan
and can be re-written in a slightly different way.
-- non-sargable
select xID ,
sName1 ,
dDOB
from tblLarge
where year(dDOB) = 2010
order by dDOB
-- sargable
select xID ,
sName1 ,
dDOB
from tblLarge
where dDOB >= '01-01-2010'
and dDOB < '01-01-2011'
order by dDOB
Execution plan and cost comparison:

Summary:
Writing efficient
query for OLTP application needs more careful consideration and understanding of
various techniques. Just satisfying the business requirement is not enough; we
also need to make sure each query is a super performer by removing non-sargable
predicates.
Nice post and thanks for your professional insight.
ReplyDelete